
John "Sean" Greenslade
Stream Audio Processing
Background and Motivation
There are a number of artists whose work I enjoy that do livestreams of their creative process. Because these streams can be quite long (some go as long as 8 hours) and these artists live in many different timezones, I'm often unable to watch their streams live. Thankfully, programs like streamlink exist which make it easy to record streams and watch them at a more convenient time.
Eventually I realized that since I had the streams recorded, I could play them back at an accelerated speed much the same way that I can "speed-listen" to podcasts. This is nice, but there's a minor issue: many streamers add some low-level background music to their streams. I'd like to hear the stream audio when the artist is speaking, but I don't want to hear the constant sound of 1.5x music (solo voice handles being sped up well, but music definitely does not).
For a while I pondered ways of detecting speech and flagging the regions that contained talking, but this seemed very complicated, difficult, and computationally expensive. Eventually I had the realization that since the background music is usually quieter than the speaker's voice, something like a simple noise gate would suffice to detect the speech. As an added bonus, noise gates can run in realtime, so this system wouldn't require a pre-processing step. That meant it could also be used on live streams if I did want to watch them as they happened in realtime.
The Linux Audio Pipeline(s)
Now that I had a concept, I needed to figure out how to execute it. The first step was to figure out how audio in Linux actually worked. Prior to this project, I had never really dug into the details. I knew there was ALSA, there was PulseAudio, and I had heard of this thing called JACK. Some quick googling revealed that ALSA was the backbone of the linux audio world, performing the acutal shuffling of bits into and out of the hardware audio interfaces. Any higher-level sound interface eventually went through ALSA for the final input / output stage. PulseAudio was the sound server of most desktop Linuxes, providing mixing, routing, resampling, and a number of other conveniences. JACK seemed to be a "professional" toolkit that served a similar purpose to Pulse, but with more focus on pro-audio and less on desktop users. From these options, PulseAudio seemed to be the logical place to start. Most of my machines already used Pulse, too.
My first attempt involved poking around in the PulseAudio documentation. I discovered the modules page, which listed the likely-looking "module-ladspa-sink," described as "Adds signal processing (for example equalizing) to a sink with a LADSPA plugin." After a quick search confirmed that LADSPA was some sort of audio filtering plugin interface, I began trying to find a noise gate LADSPA plugin.
This turned out to be something of a dead end. I learned that LADSPA was a quite old and very limited plugin format, which made finding usable plugins in the already very small world of Linux audio plugins quite difficult. In addition, the PulseAudio APIs don't expose the LADSPA plugin parameters through any of their interfaces, so tweaking parameters like the noise threshold would require unloading and reloading the plugin. Not pleasant.
After some more research (and a hint about LV2 plugins from the LADSPA Wikipedia page), I discovered the Calf Studio plugins project. The Calf Gate plugin looked perfect for what I wanted, plus I was already starting to ponder other things that could go into the audio chain such as compressors. Some streamers don't have very good microphones or audio levels, so a bit of compression would certainly help.
But at this point, I had no idea how to run an LV2 plugin. There was no native PulseAudio module for that, and everything that I found talking about LV2 plugins referred to running them inside audio DAWs like Ardour. I experimented with this briefly, but it seemed like a very heavy solution to just run one or two plugins. Also, Ardour didn't want to play nice with PulseAudio. Its only options were ALSA or JACK. So at this point, I started taking a closer look at JACK.
As I mentioned above, my inital impression of JACK was that it was similar to Pulse, but meant for more pro-audio workflows. This generally seemed to be true, with a lot of JACK documentation focusing on things like round-trip latency and realtime performance. The main problem with it for my use case was the lack of a lot of convenience factors that Pulse had. Things like remembering application volume levels, automatic routing, mixing, fallback when sound devices appeared and disappeared, and support for all of the desktop apps I use (as an example, Firefox only supports outputting audio via the Pulse APIs).
With Their Powers Combined...
Eventually, some of my googling led me to an extremely useful utility: KXStudio Carla. In its patchbay mode, Carla acts like a virtual effects rack on steroids, letting you string together audio plugins of all sorts in whatever fashion you want. I played around with launching Carla and adding in a plugin:
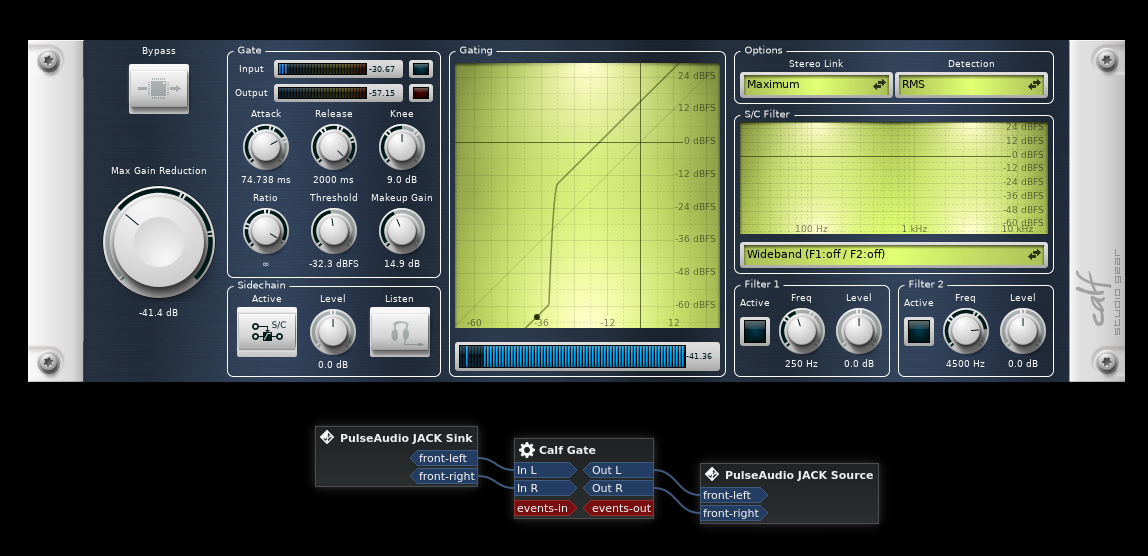
The graphical UI of the Calf plugins is really nice, allowing you to easily see the state of the processing system and understand what each control does as you adjust it in realtime.
But wait, what are those "PulseAudio JACK Sink" and "PulseAudio JACK Source" blocks? Well, those were the next piece of the puzzle. Carla really wants to run the plugins within JACK, but I want to keep PulseAudio in control of the physical hardware. As it turns out, there's a way to make the two cooperate, and it was right there in the PulseAudio modules page I had come across way back when: module-jack-sink and module-jack-source. These are PulseAudio modules that let you route sound from Pulse to JACK and vice-versa. So now I have a setup where Pulse manages the sound hardware, but certain audio can be bounced through JACK and run through my Carla effects chain before winding up back in Pulse to finally be output to the sound card. Simple, right?
Well, no, not simple. But we're getting closer to my ultimate goal. But there's a little snag with the current setup: module-jack-source. PulseAudio has some specific (if not slightly confusing) terminology for things:
| Pulse Name | Direction (Application Perspective) | Description |
|---|---|---|
| sink | output | Hardware device that feeds sound out (e.g. a headphone jack) |
| source | input | Hardware device that accepts sound in (e.g. a microphone) |
| sink input | output | Application stream that provides sound intended for an output device |
| source output | input | Application stream that accepts sound from an input device |
Module-jack-sink creates a virtual sink (output device) in Pulse that takes whatever is being fed to it and sends it out a JACK port. This is exactly what we want: I can feed the video playback to this virtual sink and now Carla can send it to my plugins. The snag is on the other end, the module-jack-source. This takes the feed from JACK and produces a virtual Pulse source (input device). But sources in Pulse are like microphones. Sources are meant to be consumed by recording applications, not fed out to sinks. Ideally what we would like is a module-jack-sink-input, but that doesn't exist. So to map the virtual source back to a sink, we need another Pulse module: module-loopback. We point the loopback's input to the virtual JACK source, and the loopback's output to the real soundcard sink. Here's a diagram of our current path so far:
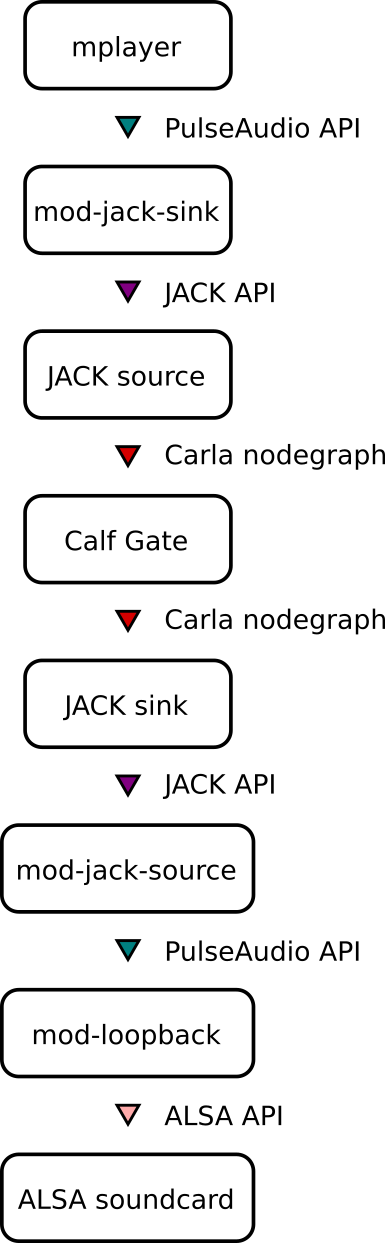
At this point, you may look at that crazy flow and wonder how much latency it's introducing. I haven't done any exact measurements, but by my ear it's approximately 100 ms. Thankfully, my video player (mplayer / smplayer) supports an audio sync offset command, so I just set the player to +100 ms and everything stays nicely in sync.
Bringing Music into the Mix
So now I have a working noise gate, but there's a lot of room for improvement. If I play my own music, I have to set it very low to be able to hear the streamer's voice over it. With most streams that I watch, the voice is intermittent. There could be long stretches of silence, and I'd rather hear my music at full volume during that time. For this, we can use an audio processing technique called sidechaining.
What is sidechaining? Broadly speaking, it's using the level of one sound to manipulate an effect applied to a different sound. In this case, the effect I'm looking for is called ducking. When the sound of the streamer talking starts coming through, I want the sound of the music to get quieter. Poking through the plugins that Calf provides, the sidechain compressor looks like it will do the job. A normal compressor has just one flow of audio, reducing the volume of its output based on the observed volume of its input. The sidechain compressor takes in a secondary stream and uses the volume of that stream to modulate the volume of the main audio stream. The audio from the sidechain input isn't fed out anywhere, just observed.
So now we need two separate sound sources, the stream audio and the music. This is easy enough to accomplish, just add another module-jack-sink to Pulse. Let's see the Carla setup now:
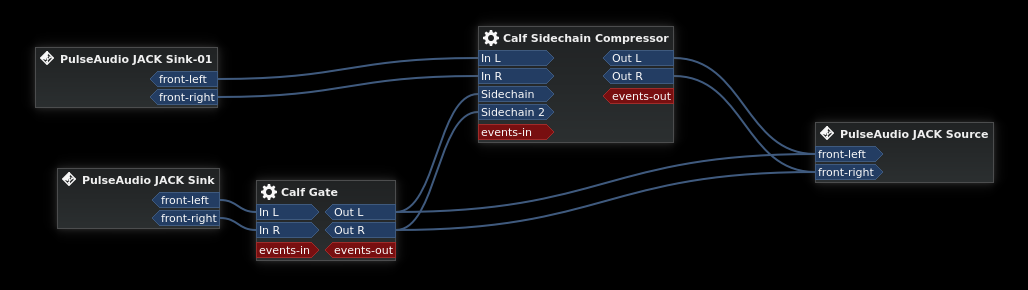
Now we can start to see the real possibilities of the full Carla/JACK nodegraph. Recall that the sidechain compressor will not output the sound from its sidechain input. In this case, that's the sound of the livestreamer, which we do want to hear. So the output from the gate is routed both to the sidechain input and to the system output.
Automation
At this point, the names of the elements are starting to become confusing. To make the setup cleaner (and easier to trigger and modify), I wrapped all the Pulse, JACK, and Carla commands into a shell script:
jack_control start
# Jack -> Pulse return source
PAM1=$(pactl load-module module-jack-source source_name=pulse_return client_name=pulse_return connect=false)
# Pulse return source -> Sink loopback
PAM2=$(pactl load-module module-loopback latency_msec=10 sink=alsa_output.usb-PreSonus_Audio_AudioBox_USB-01.analog-stereo source=pulse_return source_dont_move=true sink_dont_move=true)
# Pulse sink -> Jack (no fx, just passthrough)
PAM3=$(pactl load-module module-jack-sink sink_name=pulse_send_nofx client_name=pulse_send_nofx connect=false)
# Pulse sink -> Jack (Gate & Compressor)
PAM4=$(pactl load-module module-jack-sink sink_name=pulse_send_gatecomp client_name=pulse_send_gatecomp connect=false)
if [ $# -eq 1 ]; then
sudo nice -n -11 sudo -u sean carla ~/carla_patches/$1.carxp
else
carla ~/carla_patches/launchjack.carxp
fi
pactl unload-module $PAM4
pactl unload-module $PAM3
pactl unload-module $PAM2
pactl unload-module $PAM1
jack_control stop
There are a few little extras in this script. It accepts a string as the argument to load different Carla presets from a directory, otherwise it loads a simple passthrough preset for customization. It also calls Carla with a niceness of -11 to ensure that the audio plugins don't get starved for CPU time if something else is using a lot of CPU.
The Final Setup
My main script that I've settled on looks like this:
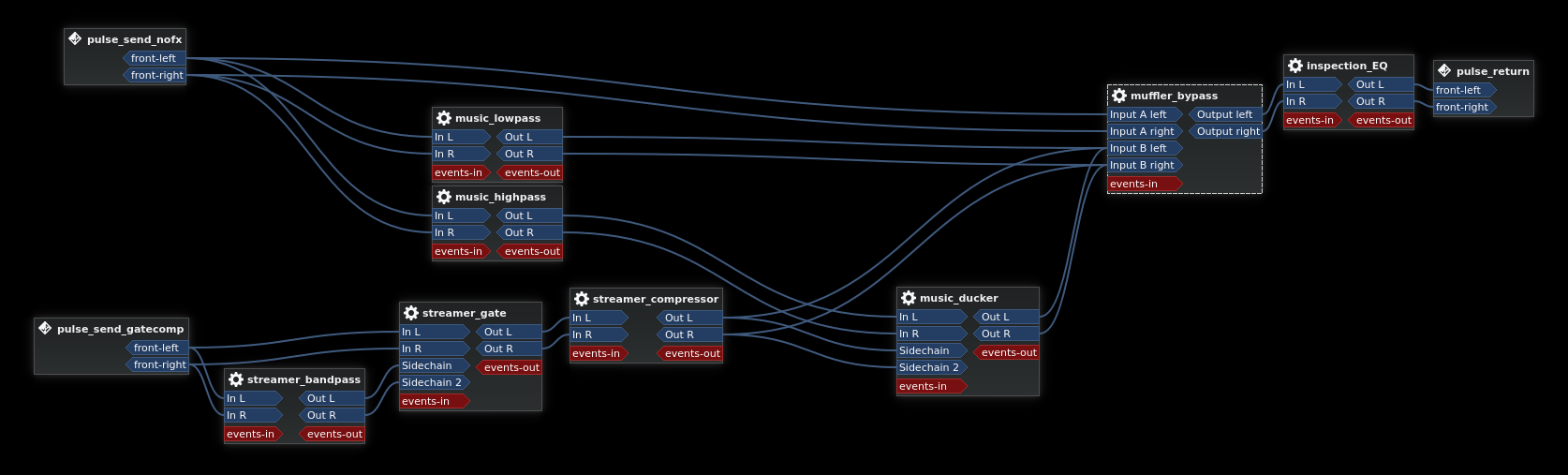
Some of the names are left over from previous iterations / experiments (including the name of this preset, "unmufflegate," which was meant as an alternative to the previous "mufflegate" preset that attempted to muffle part of the streamer's audio to cut down on the audibility of their music).
The pulse_send_nofx virtual sink is what supplies the music, and the pulse_send_gatecomp virtual sink supplies the streamer audio. This routing is set up in Pulse through the pavucontrol utility, which nicely displays the descriptive names I've given to the sinks:
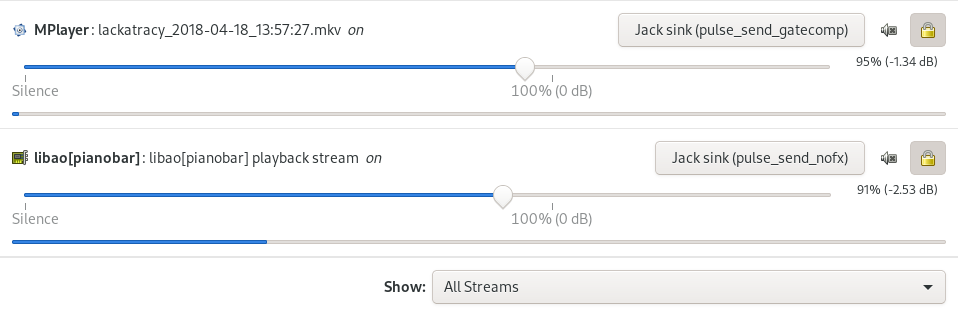
Because this setup is fairly complex, I'll break it down into sections.
Streamer Input
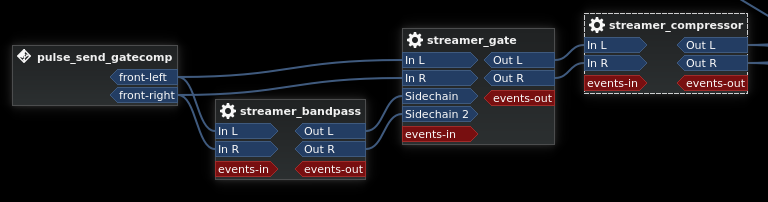
The streamer gate has been upgraded to a sidechain gate with an equalizer on the sidechain input. This equalizer cuts out a bunch of the low and high frequencies to help prevent any music present in the stream from accidentally triggering the gate. This is needed for some streams where the music is nearly as loud as the streamer's voice.
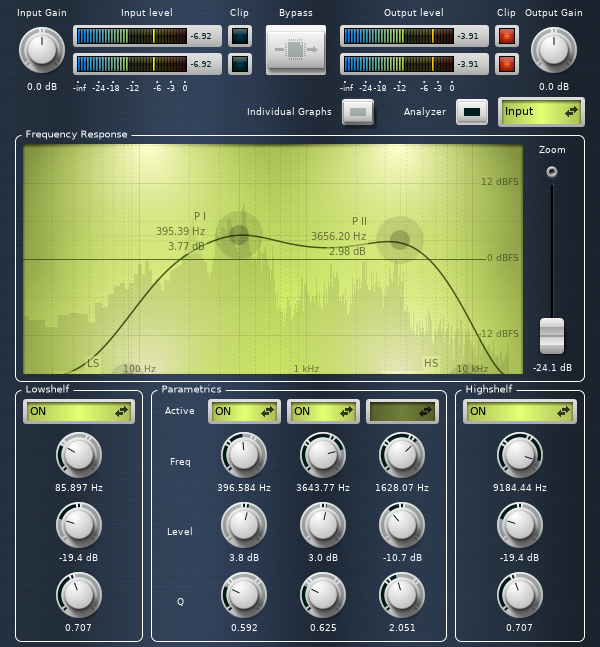
The Calf UI for the streamer_bandpass equalizer.
After the gate, there's a compressor set to some very extreme compression with a lot of makeup gain. This is to compensate for inconsistent streamer voice volumes and differences between streamers. It basically acts as an auto volume adjustment for just the streamer.
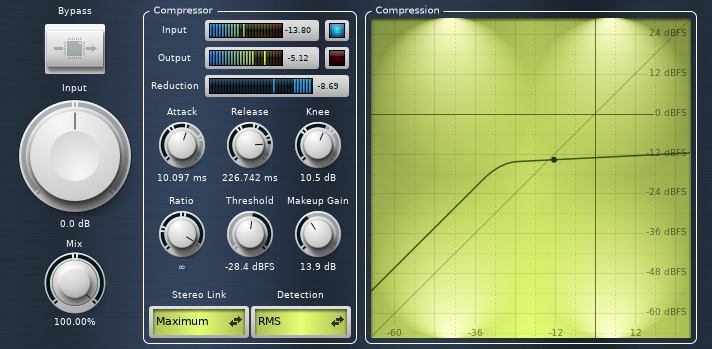
The Calf UI for the streamer_compressor.
Music Input
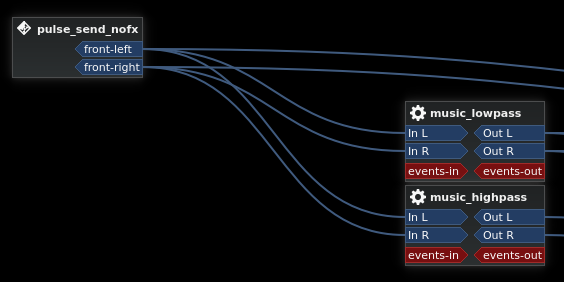
On the top side of the nodegraph, we have the input chain for my background music. This input gets fed through two equalizers that split the audio into two perfectly complimentary sections. The lowpass filter allows mostly the bass frequencies through, and the highpass filter allows mostly the midrange and treble frequencies through. The two filters have been carefully tuned to be perfectly transparent when mixed back together, so normally the sound of the music is unaffected. However, if the output from the highpass filter is lowered in volume, the music becomes muffled. The effect is similar to hearing music through a closed door or wall.
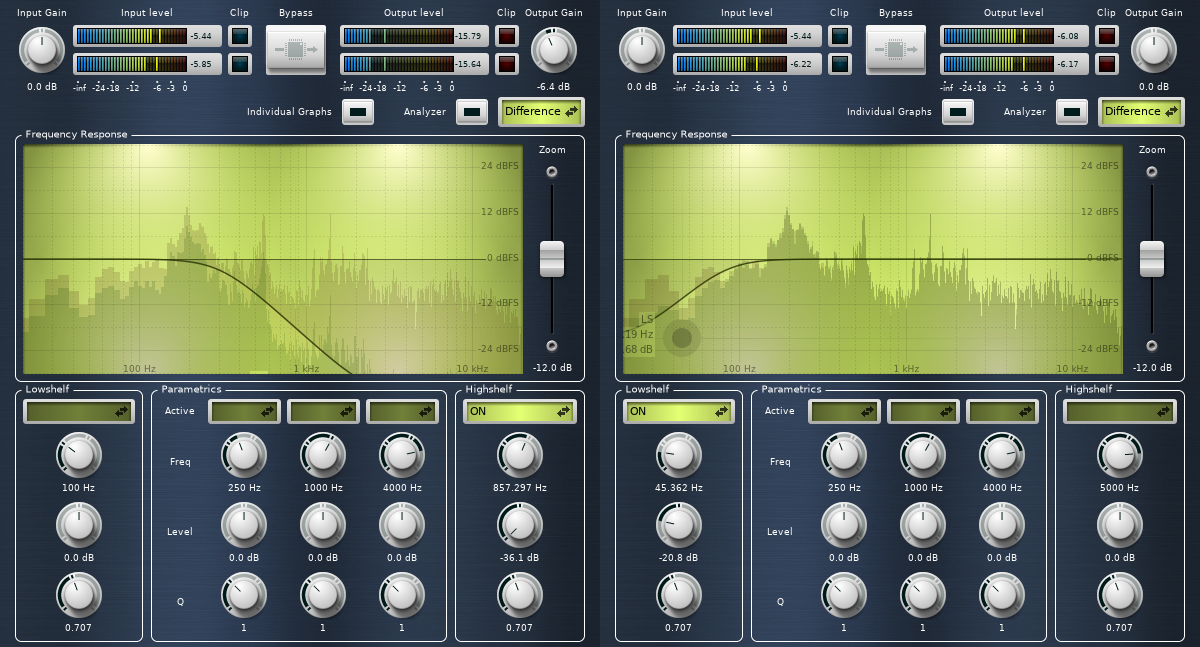
The Calf UI for the music_lowpass (left) and music_highpass (right). Note the incomplete cut of the low frequencies in the highpass and the corresponding -6 dB overall cut in the lowpass.
The Mixing Stage

The music_ducker module is where the streamer audio and the music finally meet. It is a sidechain compressor that cuts down the volume of the music whenever the streamer audio breaks through the gate. Note that it only ducks the output of the music_highpass filter. Since there's very little low-frequency content in most voices, that portion of the music can stay at full volume. I think this helps my brain keep better sync with the beat of the music, making the interruptions less distracting, but either way I like the effect it produces.
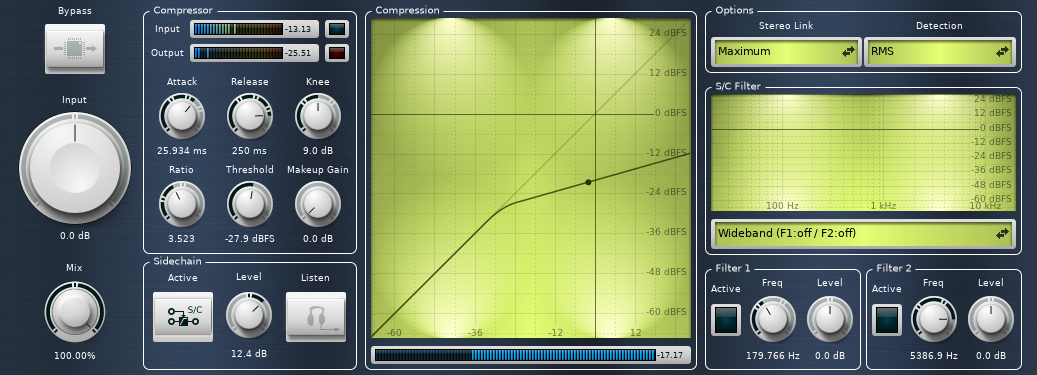
The Calf UI for the music_ducker sidechain compressor.
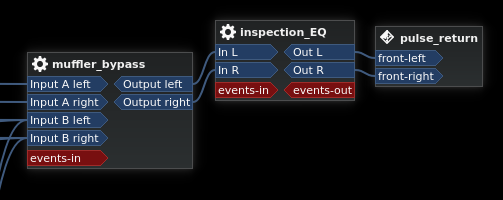
The muffler_bypass and inspection_EQ are just debugging tools left over from developing this setup. They were used to tweak the lowpass and highpass parameters to make sure they were fully transparent at all frequencies. I kept them in becuase they are occasionally useful if I need to tweak some levels.
Extra Bits
One other detail I haven't yet mentioned is that the livestream playback is actually happening on a different PC than the one with the soundcard. Here's a photo of my current battlestation:
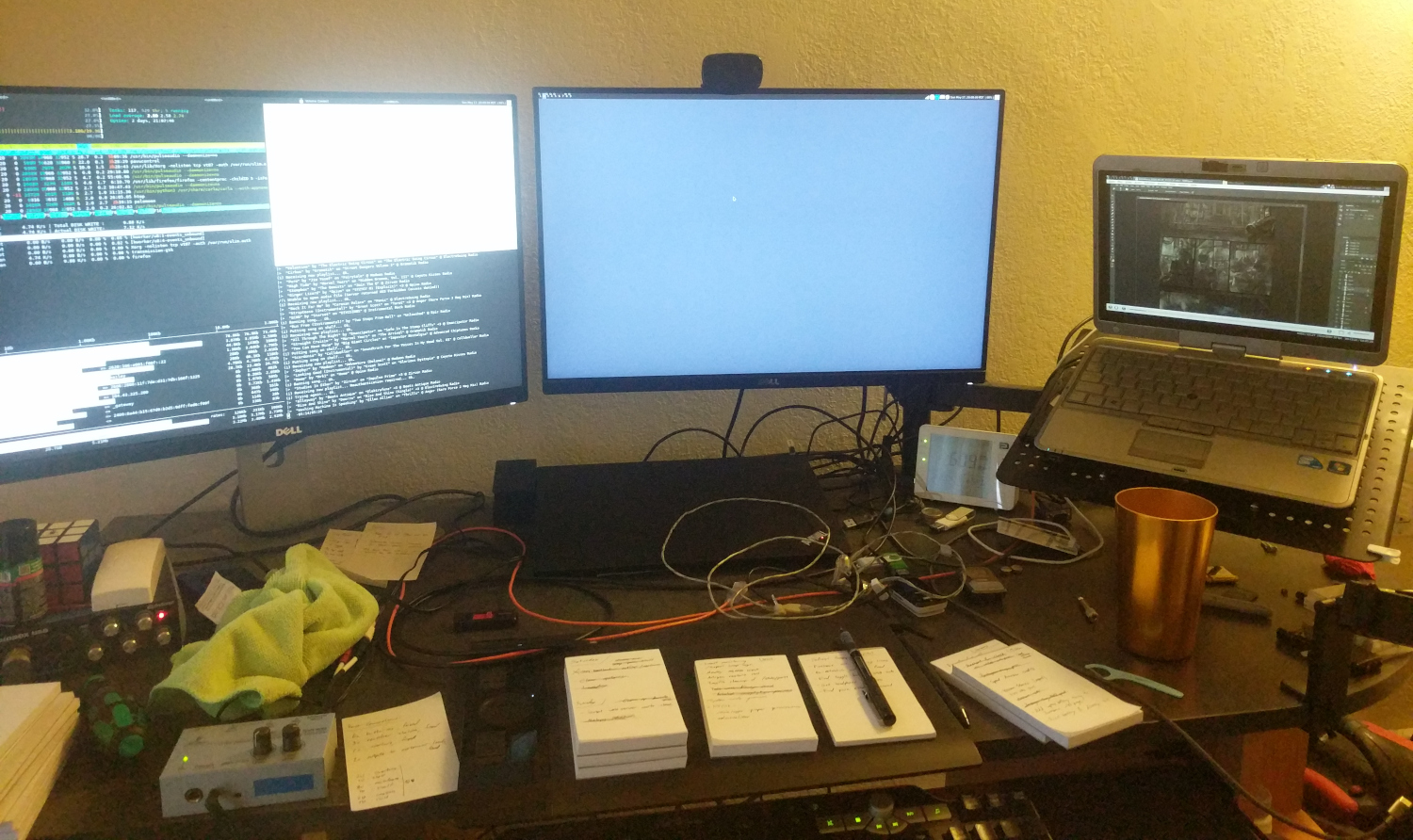 Messy, messy!
Messy, messy!The two 24-inch monitors are fed from the Thinkpad in the docking station, and the HP laptop to the right is an independent PC on the same LAN as the Thinkpad. There is a USB audio interface on the far left (underneath the Rubik's cube) that feeds through a headphone amplifier to my earphones. The Thinkpad connects to this audio interface and uses it as its primary audio device in Pulse.
The HP laptop on the right plays back the livestreams. To get the audio into the Thinkpad, I make use of PulseAudio's native network protocol. This involved uncommenting the following line in /etc/pulse/default.pa:
I also had to sync the ~/.config/pulse/cookie file between the two PCs. With that, routing audio over the network is as simple as adding "PULSE_SERVER=<Thinkpad hostname>" to the beginnning of any command. It's definitely preferable to do this over a wired network, but I've found that it does work reasonably well over WiFi as long as the link isn't saturated.
Miscellany
For a while, I struggled with an issue where the launching of plugins in Carla would fail after a certain number were loaded. The issue turned out to be a memory limits problem, and was fixed by adding the following lines to /etc/security/limits.d/10-gcr.conf:
@audio soft memlock 1024
Note that my user is a member of the audio group.
Conclusion
This system works quite well for my (admittedly somewhat weird) use case. The only thing I usually have to touch is the gate threshold in streamer_gate. This is due to the variation in the absolute audio levels between different streamers. Some streamers have very loud music (or a very soft voice), which takes a bit of careful tweaking to get the threshold just right.
Hopefully this article can inspire other uses of audio plugin setups in Linux. This system is extremely flexible, and I could see many other ways of using it. This writeup was motivated by someone asking on the pulseaudio-discuss mailing list how to mix music and microphone streams together into an application that records from just one device. In that thread I described a PulseAudio-only implementation, but that could easily be accomplished with this setup as well.
As always, my contact info is available from the link in the top navbar. I welcome any feedback or questions anyone has about this setup. I'd be happy to dive into even more detail on things if people are interested.